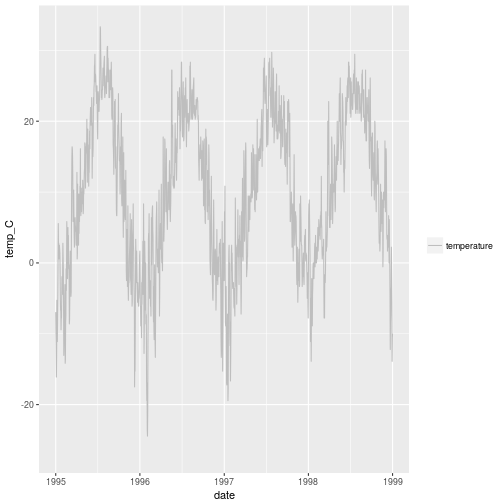
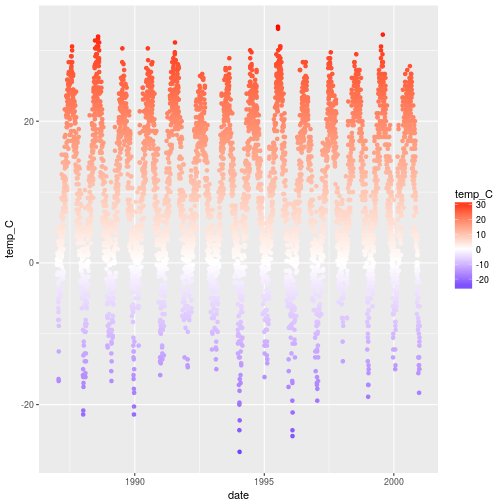
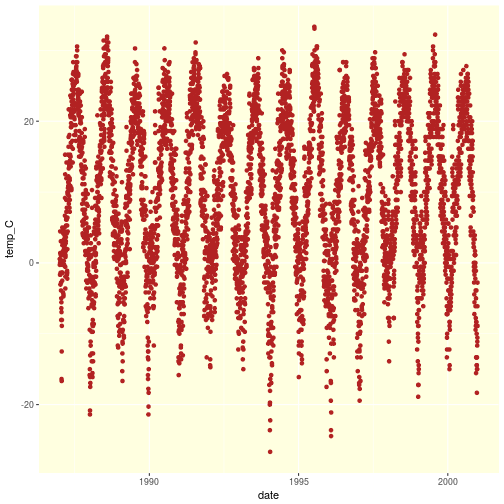
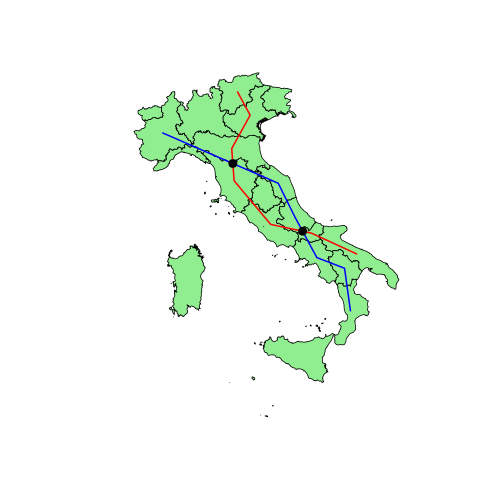
getOption("defaultPackages")
## [1] "datasets" "utils" "grDevices" "graphics" "stats" "methods"
(.packages(all.available=TRUE))
## [1] "abind" "acepack"
## [3] "ada" "ade4"
## [5] "adegenet" "adegraphics"
## [7] "adephylo" "ADGofTest"
## [9] "AER" "alabama"
## [11] "amap" "animation"
## [13] "ape" "aplpack"
## [15] "arm" "arules"
## [17] "arulesViz" "ash"
## [19] "assertthat" "backports"
## [21] "base64enc" "BB"
## [23] "bcp" "bdsmatrix"
## [25] "BH" "biclust"
## [27] "biglm" "bindr"
## [29] "bindrcpp" "BiocInstaller"
## [31] "bipartite" "bit"
## [33] "bit64" "bitops"
## [35] "BLCOP" "blob"
## [37] "bold" "brew"
## [39] "brglm" "broom"
## [41] "ca" "callr"
## [43] "car" "carData"
## [45] "caret" "cartography"
## [47] "catdata" "caTools"
## [49] "cba" "cccp"
## [51] "cellranger" "checkmate"
## [53] "chron" "CircStats"
## [55] "classInt" "cli"
## [57] "clipr" "clusterGeneration"
## [59] "clv" "coda"
## [61] "coin" "colorspace"
## [63] "combinat" "commonmark"
## [65] "Compositional" "config"
## [67] "contfrac" "copula"
## [69] "corrgram" "corrplot"
## [71] "covr" "covRobust"
## [73] "crayon" "crosstalk"
## [75] "crul" "cubature"
## [77] "curl" "CVST"
## [79] "cvTools" "data.table"
## [81] "DBI" "dbplyr"
## [83] "ddalpha" "debugme"
## [85] "deldir" "dendextend"
## [87] "dendroextras" "DEoptim"
## [89] "DEoptimR" "desc"
## [91] "descr" "deSolve"
## [93] "devtools" "dfoptim"
## [95] "dichromat" "digest"
## [97] "dimRed" "diptest"
## [99] "distr" "distrEx"
## [101] "DistributionUtils" "doBy"
## [103] "doMC" "doParallel"
## [105] "doRNG" "dotCall64"
## [107] "downloader" "dplR"
## [109] "dplyr" "DRR"
## [111] "DT" "dtplyr"
## [113] "dtw" "dynlm"
## [115] "e1071" "ecodist"
## [117] "ECOSolveR" "effects"
## [119] "ellipse" "elliptic"
## [121] "emplik" "enaR"
## [123] "energy" "EnvStats"
## [125] "eva" "evaluate"
## [127] "evir" "expm"
## [129] "FactoMineR" "fAssets"
## [131] "fastmatch" "fBasics"
## [133] "fCopulae" "fGarch"
## [135] "fields" "fit.models"
## [137] "flashClust" "flexclust"
## [139] "flexmix" "flows"
## [141] "fMultivar" "FNN"
## [143] "forcats" "foreach"
## [145] "forecast" "formatR"
## [147] "Formula" "fpc"
## [149] "fPortfolio" "fracdiff"
## [151] "FRAPO" "fts"
## [153] "gam" "gamair"
## [155] "gamlss" "gamlss.data"
## [157] "gamlss.dist" "GB2"
## [159] "gbm" "gclus"
## [161] "gdata" "GeneralizedHyperbolic"
## [163] "geometry" "geoR"
## [165] "geosphere" "GGally"
## [167] "ggcorrplot" "ggdendro"
## [169] "ggmap" "ggnet"
## [171] "ggplot2" "ggplot2movies"
## [173] "ggthemes" "ggvis"
## [175] "git2r" "glmnet"
## [177] "glue" "gmodels"
## [179] "gnm" "goftest"
## [181] "googleVis" "gower"
## [183] "gplots" "gridBase"
## [185] "gridExtra" "gsl"
## [187] "gss" "gstat"
## [189] "gsubfn" "gtable"
## [191] "gtools" "gurobi"
## [193] "gWidgets" "h2o"
## [195] "haven" "hdrcde"
## [197] "hexbin" "highr"
## [199] "hmeasure" "Hmisc"
## [201] "hms" "htmlTable"
## [203] "htmltools" "htmlwidgets"
## [205] "httpcode" "httpuv"
## [207] "httr" "hypergeo"
## [209] "Icens" "igraph"
## [211] "igraphdata" "Imap"
## [213] "ineq" "inline"
## [215] "interval" "intervals"
## [217] "IntroCompFinR" "ipred"
## [219] "irlba" "ISLR"
## [221] "iterators" "jpeg"
## [223] "jsonlite" "kernlab"
## [225] "knitr" "ks"
## [227] "labeling" "laeken"
## [229] "LaF" "Lahman"
## [231] "lasso2" "latticeExtra"
## [233] "lava" "lazyeval"
## [235] "leaflet" "leaflet.extras"
## [237] "leaps" "LearnBayes"
## [239] "limSolve" "linprog"
## [241] "lme4" "lmtest"
## [243] "locfit" "logcondens"
## [245] "longmemo" "lpSolve"
## [247] "lpSolveAPI" "lubridate"
## [249] "magic" "mapproj"
## [251] "maps" "maptools"
## [253] "markdown" "markovchain"
## [255] "MASS" "matchingR"
## [257] "matlab" "Matrix"
## [259] "MatrixModels" "matrixStats"
## [261] "maxLik" "maxmatching"
## [263] "mclust" "memoise"
## [265] "mice" "microbenchmark"
## [267] "mime" "minqa"
## [269] "misc3d" "miscTools"
## [271] "missMDA" "mix"
## [273] "mixture" "MLEcens"
## [275] "mlogit" "mnormt"
## [277] "ModelMetrics" "modelr"
## [279] "modeltools" "MPV"
## [281] "MTS" "multcomp"
## [283] "multicool" "munsell"
## [285] "mvnormtest" "mvoutlier"
## [287] "mvtnorm" "nanotime"
## [289] "natserv" "nbpMatching"
## [291] "network" "networkD3"
## [293] "nloptr" "NLP"
## [295] "NMF" "nortest"
## [297] "np" "numDeriv"
## [299] "nycflights13" "odfWeave"
## [301] "openssl" "OpenStreetMap"
## [303] "opera" "optextras"
## [305] "optimx" "optmatch"
## [307] "optrees" "osmar"
## [309] "packrat" "pander"
## [311] "party" "pbkrtest"
## [313] "PBSmapping" "pcaPP"
## [315] "PerformanceAnalytics" "perm"
## [317] "permute" "pglm"
## [319] "phylobase" "pixmap"
## [321] "pkgconfig" "pkgmaker"
## [323] "PKI" "plm"
## [325] "plogr" "plotly"
## [327] "plotrix" "pls"
## [329] "plyr" "pmml"
## [331] "png" "polyclip"
## [333] "PortfolioAnalytics" "prabclus"
## [335] "praise" "prettymapr"
## [337] "prettyunits" "pROC"
## [339] "processx" "prodlim"
## [341] "profileModel" "progress"
## [343] "proto" "proxy"
## [345] "pscl" "pspline"
## [347] "psych" "purrr"
## [349] "qap" "qcc"
## [351] "quadprog" "quantmod"
## [353] "quantreg" "qvcalc"
## [355] "R.methodsS3" "R.oo"
## [357] "R.utils" "R6"
## [359] "rainbow" "RandomFields"
## [361] "RandomFieldsUtils" "randomForest"
## [363] "randomNames" "raster"
## [365] "Rcgmin" "RColorBrewer"
## [367] "Rcpp" "RcppArmadillo"
## [369] "RcppCCTZ" "RcppDE"
## [371] "RcppEigen" "RcppParallel"
## [373] "RcppRoll" "RcppZiggurat"
## [375] "RCurl" "Rdonlp2"
## [377] "readr" "readxl"
## [379] "recipes" "registry"
## [381] "ReIns" "relimp"
## [383] "rematch" "rentrez"
## [385] "reprex" "reshape2"
## [387] "reticulate" "rex"
## [389] "Rfast" "rgdal"
## [391] "rgeos" "rgl"
## [393] "RgoogleMaps" "ritis"
## [395] "RItools" "rjson"
## [397] "RJSONIO" "rlang"
## [399] "rmarkdown" "Rmdanimation"
## [401] "Rmixmod" "RMongo"
## [403] "RMySQL" "rncl"
## [405] "rneos" "RNeXML"
## [407] "rngtools" "robCompositions"
## [409] "robust" "robustbase"
## [411] "ROCR" "RODBC"
## [413] "ROI" "ROI.plugin.alabama"
## [415] "ROI.plugin.ecos" "ROI.plugin.glpk"
## [417] "ROI.plugin.ipop" "ROI.plugin.lpsolve"
## [419] "ROI.plugin.nloptr" "ROI.plugin.optimx"
## [421] "ROI.plugin.quadprog" "ROI.plugin.scs"
## [423] "ROI.plugin.symphony" "rosm"
## [425] "rotl" "roxygen2"
## [427] "rpart" "rpart.plot"
## [429] "RPostgreSQL" "rprojroot"
## [431] "rrcov" "rredlist"
## [433] "rsconnect" "Rsolnp"
## [435] "RSQLite" "rstudioapi"
## [437] "rugarch" "RUnit"
## [439] "rvest" "Rvmmin"
## [441] "rworldmap" "sampleSelection"
## [443] "sand" "sandwich"
## [445] "sas7bdat" "scales"
## [447] "scatterplot3d" "scrapeR"
## [449] "scs" "segmented"
## [451] "selectr" "seqinr"
## [453] "seriation" "setRNG"
## [455] "sf" "sfsmisc"
## [457] "sgeostat" "shapefiles"
## [459] "shiny" "SkewHyperbolic"
## [461] "slam" "slidify"
## [463] "slidifyLibraries" "sn"
## [465] "sna" "SnowballC"
## [467] "SOAR" "solrium"
## [469] "sourcetools" "sp"
## [471] "spacetime" "spam"
## [473] "SparseM" "spatstat"
## [475] "spatstat.data" "spatstat.utils"
## [477] "spd" "spdep"
## [479] "splancs" "sqldf"
## [481] "sROC" "stabledist"
## [483] "startupmsg" "statmod"
## [485] "statnet.common" "stringr"
## [487] "strucchange" "survey"
## [489] "survival" "svd"
## [491] "svUnit" "SweaveListingUtils"
## [493] "systemfit" "tau"
## [495] "taxize" "tensor"
## [497] "tensorflow" "testthat"
## [499] "textcat" "tfruns"
## [501] "TH.data" "tibble"
## [503] "tidyr" "tidyselect"
## [505] "tidyverse" "timeDate"
## [507] "timeSeries" "tis"
## [509] "tm" "transport"
## [511] "triebeard" "trimcluster"
## [513] "tripack" "truncnorm"
## [515] "truncreg" "tseries"
## [517] "TSP" "TTR"
## [519] "tweedie" "ucminf"
## [521] "udunits2" "units"
## [523] "urca" "urltools"
## [525] "uuid" "V8"
## [527] "vars" "vcd"
## [529] "vcdExtra" "vegan"
## [531] "verification" "VGAM"
## [533] "VIM" "viridis"
## [535] "viridisLite" "visNetwork"
## [537] "waveslim" "whisker"
## [539] "WikidataR" "WikipediR"
## [541] "wikitaxa" "winference"
## [543] "withr" "wordcloud"
## [545] "worrms" "wskm"
## [547] "xlsx" "xlsxjars"
## [549] "XML" "xml2"
## [551] "xtable" "xts"
## [553] "yaml" "YieldCurve"
## [555] "zipcode" "zoo"
## [557] "littler" "magrittr"
## [559] "pkgKitten" "RcppGSL"
## [561] "reshape" "Rglpk"
## [563] "rJava" "Rsymphony"
## [565] "stringi" "base"
## [567] "boot" "class"
## [569] "cluster" "codetools"
## [571] "compiler" "datasets"
## [573] "foreign" "graphics"
## [575] "grDevices" "grid"
## [577] "KernSmooth" "lattice"
## [579] "methods" "mgcv"
## [581] "nlme" "nnet"
## [583] "parallel" "spatial"
## [585] "splines" "stats"
## [587] "stats4" "tcltk"
## [589] "tools" "utils"
rm(list=ls())
options(width = 80)
library(knitr); library(htmlwidgets); library(dplyr); library(leaflet)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
library(distr,verbose=FALSE,quietly=TRUE,warn.conflicts=FALSE)
## Utilities for Start-Up Messages (version 0.9.4)
## For more information see ?"startupmsg", NEWS("startupmsg")
##
## Attaching package: 'sfsmisc'
## The following object is masked from 'package:dplyr':
##
## last
## Utilities for Sweave Together with TeX 'listings' Package (version 0.7.7)
## NOTE: Support for this package will stop soon.
## Package 'knitr' is providing the same functionality in a better way.
## Some functions from package 'base' are intentionally masked ---see SweaveListingMASK().
## Note that global options are controlled by SweaveListingoptions() ---c.f. ?"SweaveListingoptions".
## For more information see ?"SweaveListingUtils", NEWS("SweaveListingUtils")
## There is a vignette to this package; try vignette("ExampleSweaveListingUtils").
##
## Attaching package: 'SweaveListingUtils'
## The following objects are masked from 'package:base':
##
## library, require
## Object Oriented Implementation of Distributions (version 2.6.2)
## Attention: Arithmetics on distribution objects are understood as operations on corresponding random variables (r.v.s); see distrARITH().
## Some functions from package 'stats' are intentionally masked ---see distrMASK().
## Note that global options are controlled by distroptions() ---c.f. ?"distroptions".
## For more information see ?"distr", NEWS("distr"), as well as
## http://distr.r-forge.r-project.org/
## Package "distrDoc" provides a vignette to this package as well as to several extension packages; try vignette("distr").
library(distrEx,verbose=FALSE,quietly=TRUE,warn.conflicts=FALSE)
## Extensions of Package 'distr' (version 2.6.1)
## Note: Packages "e1071", "moments", "fBasics" should be attached /before/ package "distrEx". See distrExMASK().Note: Extreme value distribution functionality has been moved to
## package "RobExtremes". See distrExMOVED().
## For more information see ?"distrEx", NEWS("distrEx"), as well as
## http://distr.r-forge.r-project.org/
## Package "distrDoc" provides a vignette to this package as well as to several related packages; try vignette("distr").
library(pryr,verbose=FALSE,quietly=TRUE)
## Error in library(pryr, verbose = FALSE, quietly = TRUE): there is no package called 'pryr'
library(wordcloud,verbose=FALSE,quietly=TRUE)
library(tm,verbose=FALSE,quietly=TRUE)